
专题|DeepSeek核心技术解析:开源周洞见与金融数智化转型展望
文/招商证券股份有限公司金融科技中心AI开发团队 张甜瑾
DeepSeek的诞生标志着中国科技企业在“技术—业务—组织”三位一体协同创新领域的重大突破。通过构建以本地化部署为根基、业务场景深度适配为导向、工程化能力为支撑的三维赋能体系,该体系为证券行业及更广泛产业领域提供了高效敏捷的智能化转型方案。这一战略级创新成果的落地,不仅重塑了行业智能化升级的标杆范式,更标志着我国人工智能技术实现从“跟随者”到“引领者”的里程碑式跨越。
DeepSeek核心创新点分析
2025年1月20日,深度求索(DeepSeek)公司正式发布了其最新推理模型DeepSeek-R1。同时值得关注的是,深度求索于2025年2月24日至3月1日期间,创新性发起“技术开源周”行动。将DeepSeek V3/R1模型实践中验证的高效加速模块以源代码形式正式发布,形成从算法创新到工程落地的完整开源生态。
DeepSeek-R1此次受到广泛关注的原因主要有两点。首先,在OpenAI o1完全闭源且API价格高昂的背景下,DeepSeek团队成功复现了o1的能力,类似于2023年Meta Llama发布,为全球开发者和企业提供了可用的推理模型。其次,在有限的算力资源支持下,DeepSeek-R1通过强大的算法创新突破了算力瓶颈,展示了在资源受限条件下实现全球领先成果的可能性。此外,DeepSeek-R1还支持模型蒸馏,允许用户基于该模型训练其他专用模型,进一步推动了AI技术的普及和创新。
基于强化学习技术复现OpenAIo1能力
强化学习(Reinforcement Learning,RL)作为大模型后训练阶段的核心优化范式,在特定任务性能提升及生成式任务的人类偏好对齐中具有重要战略价值。其中具有代表性的实践范式为OpenAI研发的ChatGPT所采用的基于人类反馈的强化学习(RLHF)技术框架,其方法论体系包含三阶段系统构建:首先基于预训练构建通用语言基座模型(如GPT系列);其次通过人类标注的偏好数据训练奖励模型,建立生成内容的质量评估体系;最终依托强化学习算法(如近端策略优化PPO)实施模型微调,确保输出内容在连贯性、安全性和实用性等维度达成预期目标。该技术路径虽具有显著成效,但存在较高的技术实现复杂度,其效能深度依赖于海量高质量人类反馈数据支撑,且面临训练过程中计算资源消耗巨大的挑战。
DeepSeek-R1创新性地构建了融合监督微调(SFT)与强化学习(RL)的多阶段协同训练体系,其突破性体现在自主研发的GRPO(Group Relative Policy Optimization)算法,通过采样输出平均奖励基准化技术,有效突破传统强化学习(如PPO)对大规模标注数据奖励模型的依赖瓶颈。系统化训练框架涵盖以下核心技术阶段。
冷启动阶段(Cold Start):从预训练模型DeepSeek-V3-Base(671亿参数MoE模型)出发,利用少量高质量的长链式思维(Chain of Thought,CoT)数据进行监督微调,为后续RL奠定基础,避免模型初始行为过于随机。
推理导向强化学习(Reasoning-Oriented RL):采用自研GRPO算法,通过规则定义奖励函数,从而激励模型生成逐步推理的正确解。这一阶段增强了模型的推理能力,使其自然发展出自验证、反思等行为。
拒绝采样与监督微调(Rejection Sampling & SFT):通过强化学习产出样本的质量筛选机制,构建高可信度、高可读性的优化数据集进行二次微调,有效解决语言混杂及表达流畅性问题,实现技术性能与用户体验的协同提升。
全面强化场景学习:融合人类偏好数据与安全约束条件,在保持核心推理能力的同时,全方位优化模型的可用性和安全性,确保技术落地与实际业务需求的深度契合。
展开全文
DeepSeek-R1的多阶段训练方法已被广泛验证,其论文发布后,多个开源复现项目成功实现了左右互搏持续学习的效果,进一步证明了该方法的有效性和可复现性。
有限算力下的高效大模型训练
大模型训练是一项涵盖底层硬件基础设施、软件架构设计、数据处理优化、算法创新及生态协同的复杂系统工程。为在有限算力资源条件下实现高效能模型训练,DeepSeek技术团队通过全栈式技术革新,构建了涵盖硬件适配层、中间件层及算法层的协同优化体系,形成多项具有自主知识产权的核心技术突破(如图所示)。关键创新成果如下。
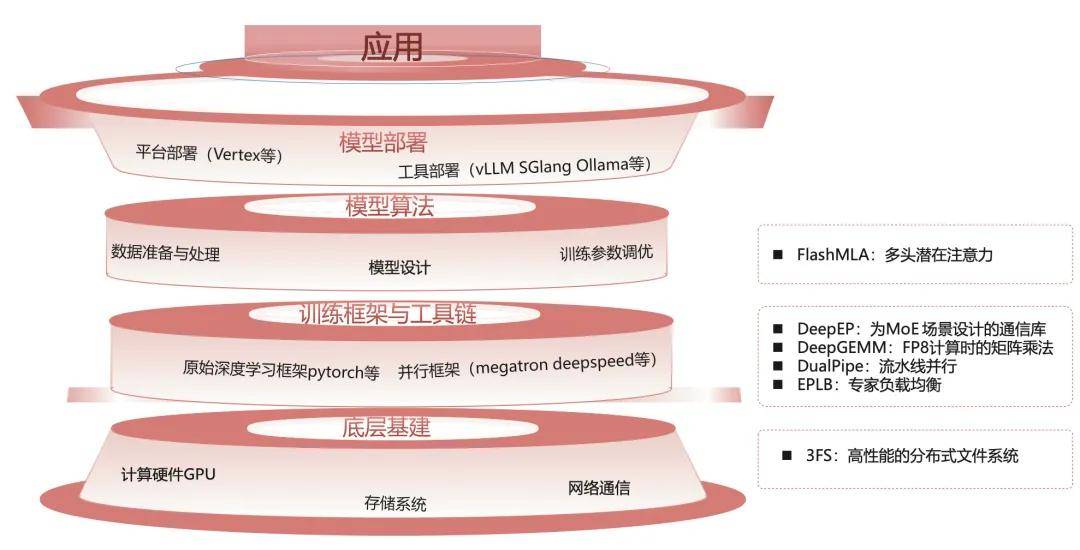
图 大模型全栈图及DeepSeek开源周相关创新
专家混合(MoE)架构:针对MoE架构中存在的专家负载均衡问题,提出了自研的细粒度专家与共享专家协同机制。该方案通过动态专家分配算法与负载均衡策略,系统性解决传统MoE架构中的专家资源利用率不均问题,实现模型训练和推理效率的显著提升,为超大规模模型训练奠定基础。
多头潜在注意力机制:针对多头注意力机制在推理时需要大量KV缓存的问题,自主研发的多头潜在注意力机制(MLA)通过潜空间映射和低秩压缩技术,在尽量保证信息完整性的前提下将KV缓存降低至最小。该技术突破不仅将推理效率提升至新高度,其核心算法代码(FlashMLA)更通过开源社区共享,推动行业技术进步。
多Token生成(MTP)机制:创新设计的MTP模块突破大模型生成中传统逐token的生成范式,实现多步前瞻性预测与上下文信息的全局耦合。该技术通过强化训练信号密度与序列生成并行度,使模型训练效率与前向推理速度获得量级提升,显著降低算力资源消耗。
深度通信优化框架(DeepEP):专为MoE架构分布式训练设计的DeepEP通信库,通过NVLink节点内高速互联与RDMA节点间通信技术融合,构建全对全(All-to-All)数据交换体系,并针对数据分发(Dispatch)和合并(Combine)操作进行深度优化。这一设计确保了数据在多GPU间的高速传输,有效缩短通信时间,提升分布式训练的整体性能与稳定性。
高性能矩阵乘法库(DeepGEMM):针对FP8精度优化需求自主研发的矩阵计算引擎,支持普通GEMM及MoE分组计算,通过引入CUDA核心两级累加(提升)技术和轻量级即时编译(JIT)模块,为低精度训练提供可靠算力保障。
双向流水线并行(DualPipe与EPLB):DualPipe是为提升训练中GPU利用率而设计并实现的流水线并行,通过完全重叠前向与后向计算和通信阶段,有效减少流水线中的空闲时间,显著提升硬件资源利用率。EPLB的核心在于其冗余专家策略,通过对高负载专家进行复制,并通过启发式算法合理分配这些复制的专家到各个GPU上,以达到最佳的负载均衡效果。
超高速存储系统(3FS):为提升大规模训练中模型数据保存速度而设计的高性能分布式文件系统,在180节点集群中实现了6.6TiB/s的总读取吞吐量,每个客户端节点的KVCache查询峰值吞吐量超过40GiB/s,为超大规模模型训练提供企业级存储解决方案。
Inference System Overview:为了V3/R1部署之后有更高的吞吐量和更低的延迟,推理阶段采用跨节点专家并行架构与双批次重叠策略,叠加注意力分层技术,实现545%的成本效益比。
DeepSeek-R1本地化部署建议
DeepSeek-R1此次的开源模型包括671B全参数量和基于Qwen/Llama系列的蒸馏版本在内的完整模型矩阵,我们对各版本参数和部署硬件的配置梳理见表1。
表1 DeepSeek全系列模型部署建议
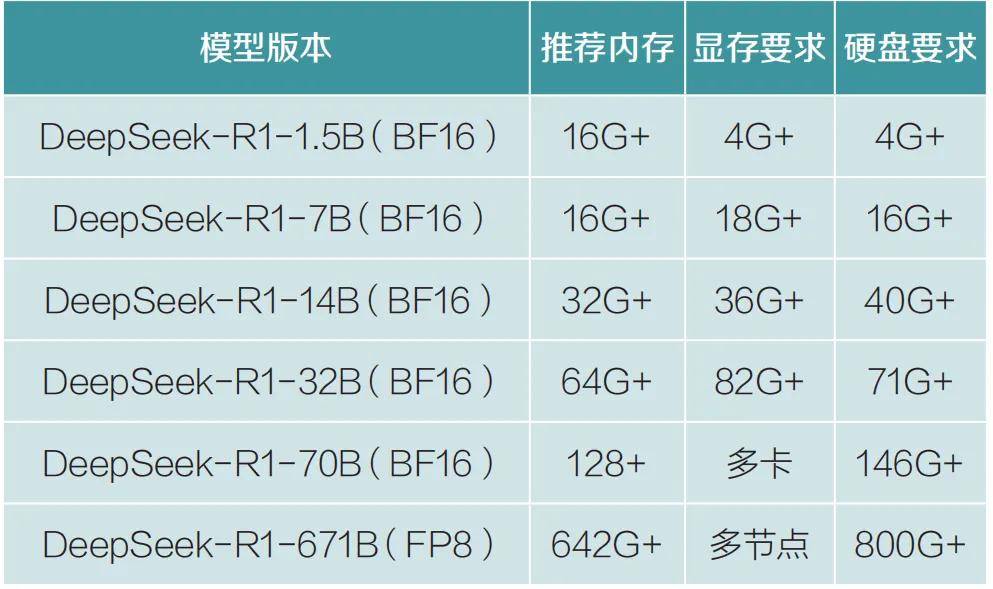
通用部署建议:在部署DeepSeek-R1模型时,建议采用以下通用策略以优化性能和资源利用效率。首先,通过4-bit或8-bit量化技术,可显著降低显存占用,减少幅度可达30%至50%,从而在有限的硬件资源上支持更大规模的模型部署。其次,结合高效的推理框架如vLLM或SGLang,其动态批次处理与内存优化能够进一步提升模型的推理速度和效率。此外,对于参数量较大的模型(如70B及以上),建议优先考虑云平台部署。最后,部署32B及以上参数量的模型时,需确保配备高功率电源和高效的散热系统,以保障系统的稳定运行。
昇腾910B部署建议:针对华为昇腾910B芯片的671B全参数版部署,有两种权重选择,BF16权重和W8A8量化权重。其中,采用BF16权重进行推理时,至少需要4台Atlas 800T A2(8×64G)服务器,单路并发推理速度可达36tokens/秒,以体验为基准可以达到64路并发。而采用W8A8量化权重进行推理时,至少需要2台Atlas 800T A2(8×64G)服务器。为达到当前最优推理性能,各模块所需的参数配置详情具体见表2。
表2 昇腾910B部署参数
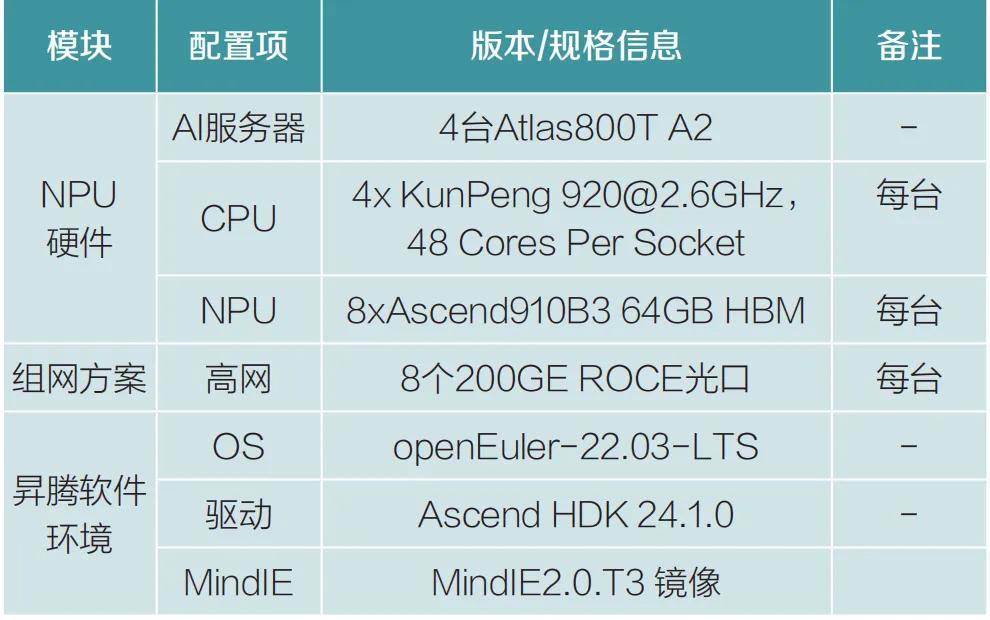
未来,华为昇腾910B会陆续增加对DeepSeek-R1中的MTP模块支持并且支持多节点分布式部署,推理速度会有进一步的提升。
DeepSeek潜在挑战
DeepSeek-R1虽在MMLU等通用基准测试中逼近GPT-4Turbo,但在Vectara推出的HHEM人工智能幻觉测试中,DeepSeek-R1显示出14.3%的幻觉率,因此金融等高精度场景的幻觉率仍制约其直接替代人工决策。当前性能最领先的GPT-4Turbo、DeepSeek-R1、Grok3均不是大模型的终局,下一代模型需平衡能力扩展(如多模态理解)与可控性强化,动态工作流编排、过程可解释性和推理性能持续优化将成为关键竞争维度。
DeepSeek对人工智能产业链的影响
DeepSeek通过开源周及其技术突破深刻影响AI生态。
芯片算力:DeepSeek以算法优化降低对高端GPU依赖,推动算力市场向“训练与推理并重”转型。端侧AI普及弥补性能与成本短板,边缘与云计算协同成趋势。DeepSeek的普惠化并未削减算力需求,反而因长尾场景激活与推理复杂度提升,推动算力消耗量级跃升。
模型技术:大模型竞争将从“参数规模”转向“架构创新”,模型开发将更加注重“算法-成本-场景”的平衡,并且DeepSeek公开利润率也说明了极限的Infra工程可以带来利润的提升,未来算法公司会加大对Infra的重视程度。中小厂商有望凭借算法突破获得弯道超车的机会。尤其开源更加降低了AI基础设施开发的门槛,使中小团队也能够受益于前沿技术。
开源繁荣:此次DeepSeek采用较为宽松的MIT开源协议,冲击OpenAI闭源模式,促进开源繁荣。未来,开源将成为技术普及核心路径,迫使闭源巨头开放细节。
智能化升级:AI对企业/行业的影响可分为三类。AI+产品,通过创造真实需求提升客户付费意愿;AI+算力,通过AI工具替代人力降低成本,如游戏行业的广泛应用;AI+服务,通过提升产品力抢占市场份额。
DeepSeek对金融业的影响及应对
技术体系变革:DeepSeek推动AI原生架构,从分层开发转向全链路自动化,支持Agent编排、在线更新与训推一体;智能副驾(如代码自动补全、测试用例生成)普及提升IT研发效率;运维自愈体系实现“感知-修复”自动化,优化响应效率,解放技术实现边界。
开发与数据模式重塑:低代码平台通过自然语言生成模块重构交付模式;自动化标注与模型蒸馏提速小模型迭代至日级;“教师-学生”迁移提升专用模型准确率,解决泛化不足痛点,驱动数据闭环。
业务与组织重构:DeepSeek助力存量场景智能化与新场景开拓;组织向跨域协同网络演进,打破部门壁垒,催生AI训练师等人机共生岗位,人机效能指数成核心指标,推动业务与组织形态升级。
未来展望:技术普惠与生态协同
技术普惠化:随着模型蒸馏和开源生态成熟,不论企业规模大小,均可基于DeepSeek快速构建垂直场景模型,推动AI技术“下沉”。
生态协同:与开源社区协同,当前HuggingFace社区已孵化超千个衍生模型;金融机构+科技产业协同,如联合打造“AI+业务场景实验室”,探索更多可能。
金融行业:随着DeepSeek的极大开源,会给金融行业的多种业务场景如投顾、投研等带来新的范式。
(此文刊发于《金融电子化》2025年4月上半月刊)
相关文章
-

科创板晚报|臻宝科技科创板IPO获上市委会议通过
-
每周股票复盘:西藏药业(600211)华西药业质押展期1,876万股
-
共同药业(300966)发布关于向2026年限制性股票激励计划激励对象首次授予限制性股票的公告,5月25日股价下跌0.87%
-
股票行情快报:天新药业(603235)5月25日主力资金净买入2.79万元
-
广济药业:回购注销263.07万股限制性股票减少注册资本263.07万元
-
股票行情快报:西藏药业(600211)5月25日主力资金净卖出2262.62万元
-
40分钟直达上海!预计明年7月具备开通运营条件
-
郑丽文:全世界都不支持“台独”,赖清德为什么不敢正面回答何时下架“台独党纲”






评论