
Stata —数据统计分析软件包

Stata 19 现已发布!您可以在我们的网站上看到所有新功能。 表格、图形、框架和 “Do-file 编辑器”(Do-file Editor)都有许多改进,将简化您的工作流程。 许多令人兴奋的新统计功能包括:
01【Stata19 新功能】通过 H2O 进行机器学习:集合决策树
02【Stata19 新功能】相关随机效应 (CRE) 模型
03【Stata19 新功能】条件平均治疗效果(CATEs)
04【Stata19 新功能】面板数据向量自回归模型
05【Stata19 新功能】逻辑回归的功率分析
06【Stata19 新功能】高维固定效应(HDFE)
07【Stata19 新功能】通过工具变量的结构向量自回归模型
08【Stata19 新功能】贝叶斯线性模型变量选择
09【Stata19 新功能】用于区间删失多事件数据的边际 Cox PH 模型
10【Stata19 新功能】工具变量局部投影 IRFs
11【Stata19 新功能】不对称拉普拉斯贝叶斯模型
12【Stata19 新功能】贝叶斯自举法
13【Stata19 新功能】Do-file 编辑器功能增强
14【Stata19 新功能】控制函数线性模型和概率模型
15【Stata19 新功能】图形: 条形图 CI、热图等
16【Stata19 新功能】贝叶斯分位数回归
17【Stata19 新功能】功能更强大的表格:更轻松的统计、导出功能及更多实用功能
18【Stata19 新功能】工具变量回归中弱工具的稳健推断
19【Stata19 新功能】多个数据集:修改一组帧
20【Stata19 新功能】蒙德拉克规格测试
1、机器学习功能的扩展:集合决策树
Stata19版本官方命令引入另一类常用的机器学习方法,即基于决策树(decision trees)的集成学习方法(ensemble learning),包括随机森林(random forest)与梯度提升法(gradient boosting machine)
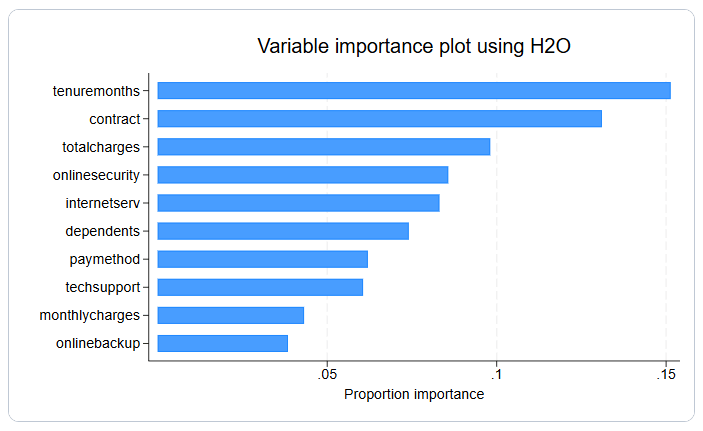
Stata 19提供了一套新的h2oml命令,可轻松地接入开源的大数据机器学习平台H2O,针对回归(regression)或分类(classification)问题使用随机森林或梯度提升法。H2O使得机器学习变得更加容易,有时称为AutoML。
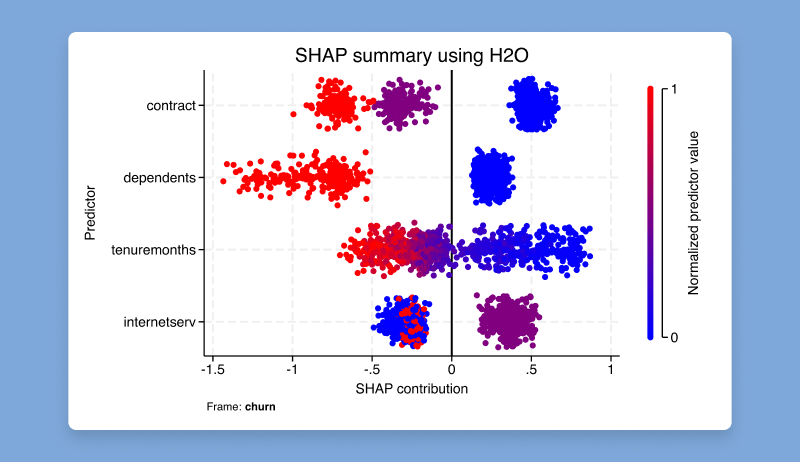
h20.png 画变量重要性图(variable importance plot):
展开全文
2、面板数据
Stata 19引入了有关面板数据的若干新命令或选择项,包括高维固定效应(high dimensional FE)、相关随机效应(correlated random effects)、面板向量自回归(panel VAR),给用户带来了强大的新功能与便利。
2.1 高维固定效应
这次Stata 19将其相应功能纳入了官方命令(无须额外命令,仅新增了一个选择项),使得操作更为简便可靠!
例如,在估计面板固定效应模型时,假设我们还想额外地控制三个分类变量(categorical variables)z1, z2与z3,只要在常规命令加上absorb()的选择项即可,类似地,我们在进行二阶段最小二乘法(2SLS)估计时,也可以使用absorb()的选择项。
2.2 相关随机效应
静态面板的两个常用模型为随机效应(random effects,简记RE)与固定效应(fixed effects,简记FE)。然而,二者均有缺点。随机效应模型不够稳健,如果解释变量与个体效应相关,则得不到一致估计。另一方面,虽然固定效应模型较为稳健,但无法估计非时变(time-invariant)变量的系数。为此,Stata 19推出了“相关随机效应”(correlated random effects,简记CRE),可以兼顾二者的优点。
CRE模型允许解释变量与个体效应相关,且时变(time-varying)变量的系数估计值与FE完全相同,故本质上为FE模型。在算法上,CRE估计量将时变变量的组平均值加入混合回归中,故可视为一种控制函数法(通过时变变量的组平均值来控制遗漏变量)。由于CRE未做组内离差变换,故也可以估计出非时变变量的系数,这是CRE的最大优点。
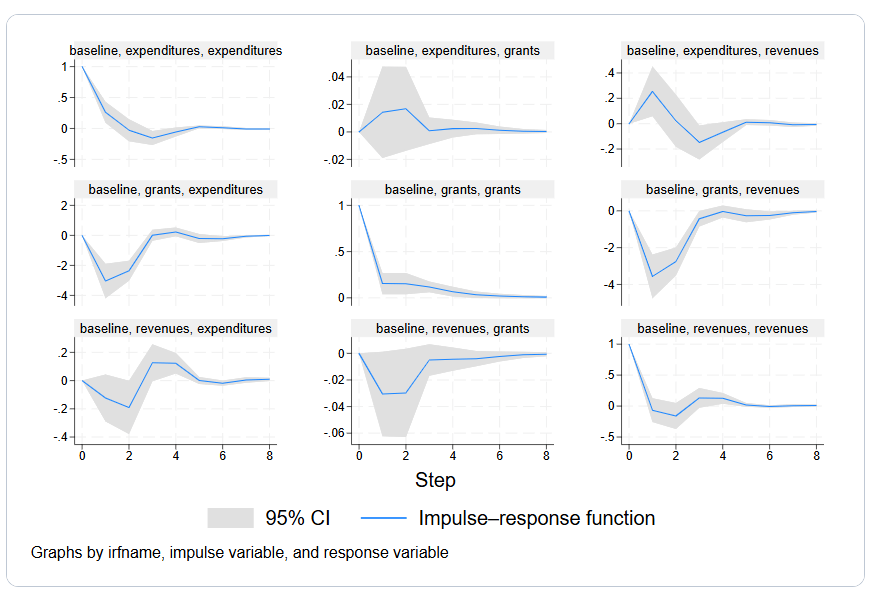
2.3 面板向量自回归
向量自回归(vector autoregressoin,简记VAR)是常见的时间序列模型,但由于VAR模型的待估参数较多,故一般需要较长的时间维度。面板向量自回归(panel vector autogression,简记Panel VAR)将VAR模型推广到面板数据中。面板VAR模型既包含个体固定效应,也包括被解释变量的滞后项,故可视为动态面板模型(dynamic panel-data model)与VAR模型的结合。相应地,面板VAR模型的估计方法类似于动态面板,主要使用广义矩估计(generalized method of moment,简记GMM)。其渐近理论要求横截面单位的数量趋向无穷大,故适用于时间维度较短的短面板。
3、因果推断
因果推断始终是实证研究的核心方法。Stata 19在因果推断方面的功能也进一步加强,新推出的方法包括条件平均处理效应(CATE)以及有关工具变量法的一些新方法。
3.1 条件平均处理效应
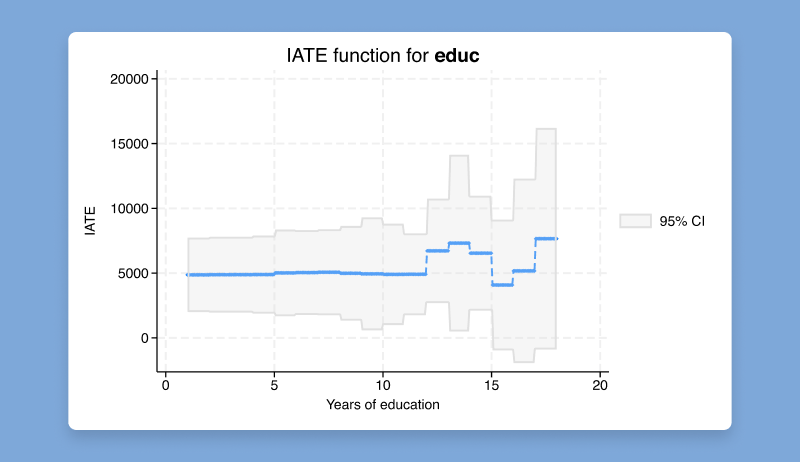
因果推断关注的对象一般为全样本的平均处理效应(average treatment effect,简记ATE)或处理组平均处理效应(average treatment effect on the treated,简记ATT或ATET)。然而,不同个体的处理效应很可能存在异质性,而研究者有时感兴趣,异质性处理效应如何随着个体特征而变。例如,电商平台可能关心价格折扣如何影响消费者行为,而价格折扣的处理效应可能依赖于消费者的年龄与收入。
为此,Stata 19推出了全新的cate命令,用于估计“条件平均处理效应”(conditional average treatment effect,简记CATE),即在给定某种个体特征条件下的平均处理效应。命令cate可以估计三种不同类型的CATE,包括“个体平均处理效应”(individualized average treatment effect),“分组平均处理效应”(group average treatment effect)及“排序分组平均处理效应”(sorted group average treatment effect)。除了估计外,cate系列命令还可进行预测、可视化及统计推断。
Stata 19的cate命令功能强大、灵活而稳健。例如,在对结果回归(outcome regression)与处理效应模型(treatment models)建模时,可使用参数模型(parametric models),拉索估计量(lasso)或广义随机森林(generalized random forest;有时也称为“诚实森林”,即honest forest)。该命令提供了两个稳健估计量,即“偏效应过滤”(partialling out)与“增强逆概加权”(augmented inverse probability weighting),其中后者为双稳健估计量(doubly robust estimator);并使用“交叉拟合”(cross-fitting)以避免过拟合(overfitting)。
3.2 控制函数法
传统的工具变量法一般使用二阶段最小二乘法(two-stage least squares,简记2SLS)。2SLS之所以成立,是因为第一阶段回归为线性模型,而线性回归的OLS估计具有正交性。这也意味着,2SLS一般无法推广到非线性模型中;例如,当内生变量为虚拟变量时,第一阶段回归为Probit模型。
为此,Stata 19新推出了更为灵活的“控制函数法”(control function approach,简记CF),不仅可用于线性模型,而且也适用于非线性模型。
3.3 弱工具变量稳健推断
使用工具变量法进行因果推断一般要求强工具变量。在弱工具变量(weak instrument)的情况下,2SLS估计量变得不可靠,即使在大样本下。这是因为2SLS估计量其实是一个比值(ratio),而在弱工具变量的情况下,该比值的分母接近于0,导致统计推断失效。
为此,Stata 19推出了安德森-鲁宾检验(Anderson-Rubin test),不再使用上述比值进行统计推断,故即使在弱工具变量的情况下依然稳健。
3.4 时间序列的工具变量法
Stata 19专门推出了针对时间序列的工具变量法,包括通过工具变量法估计结构VAR模型,以及使用工具变量法估计脉冲响应函数。
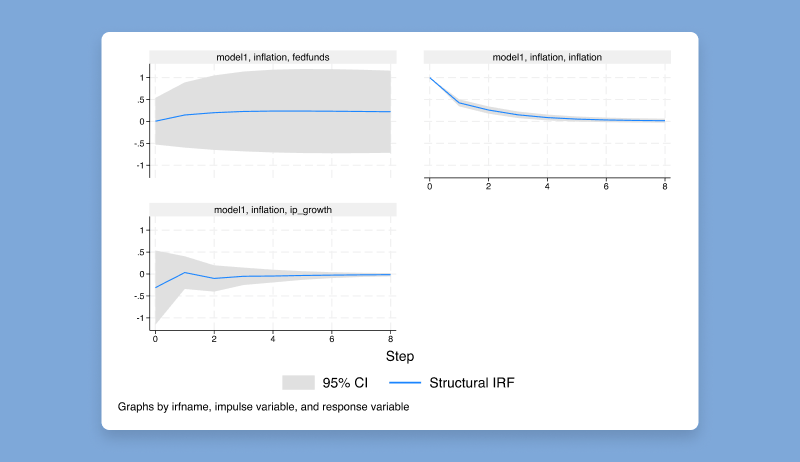
4、贝叶斯方法
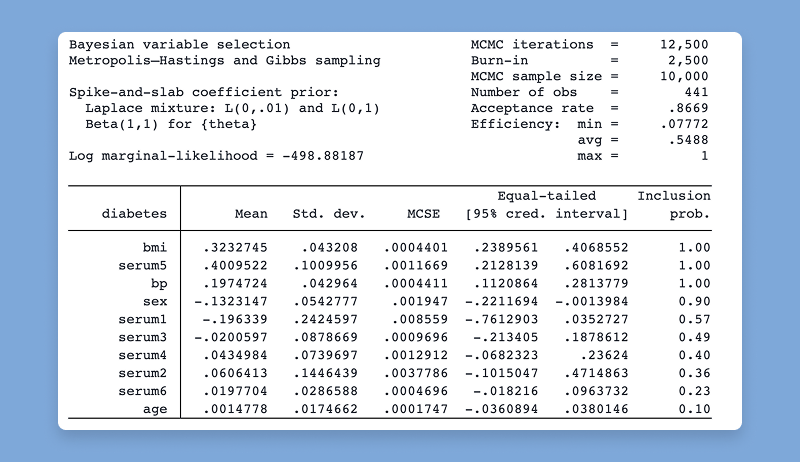
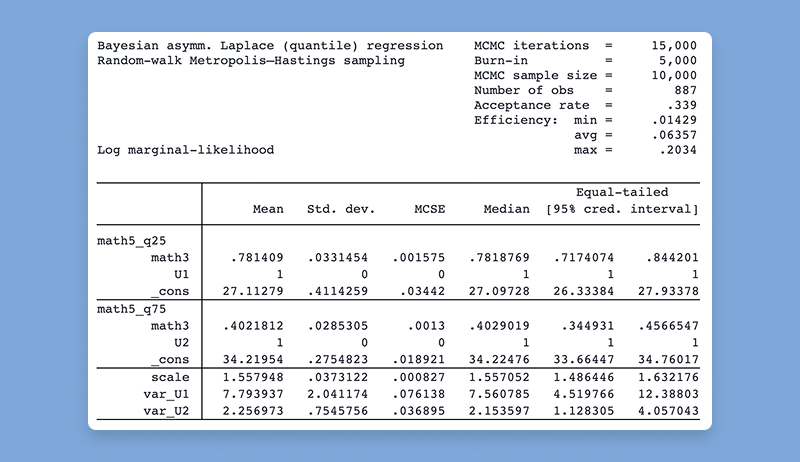
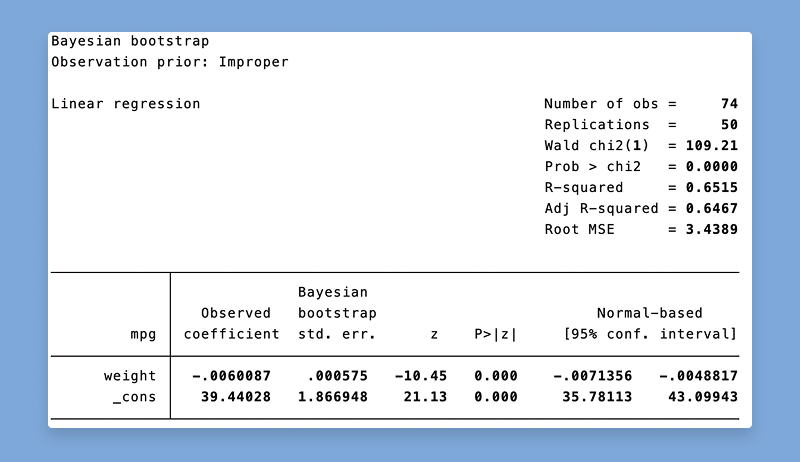
Stata 19在贝叶斯计量经济学(Bayesian econometrics)方面的功能继续得到加强,新增方法包括贝叶斯变量选择、分位数回归及自助法等。 现在可以使用新的 bayesboot 前缀,通过贝叶斯自助法在小样本中获得更精确的参数估计,并在抽样时纳入先验信息。它可与官方命令或社区贡献命令搭配使用。
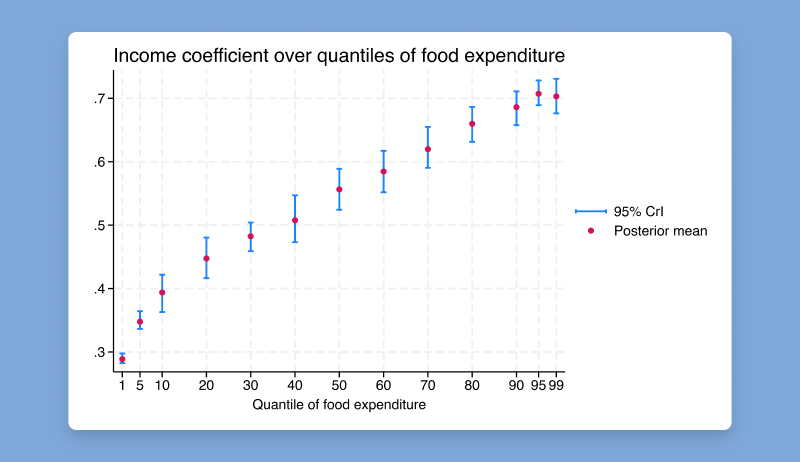
使用贝叶斯方法从变量x1-x100中进行变量选择:
使用贝叶斯方法进行分位数回归(quantile regression):
使用贝叶斯自助法(Bayesian bootstrap)估计x的均值:
5、其他计量方法
Stata 19还提供了其他方面的计量新方法,包括久期模型、相关系数的元分析、潜类别模型等。
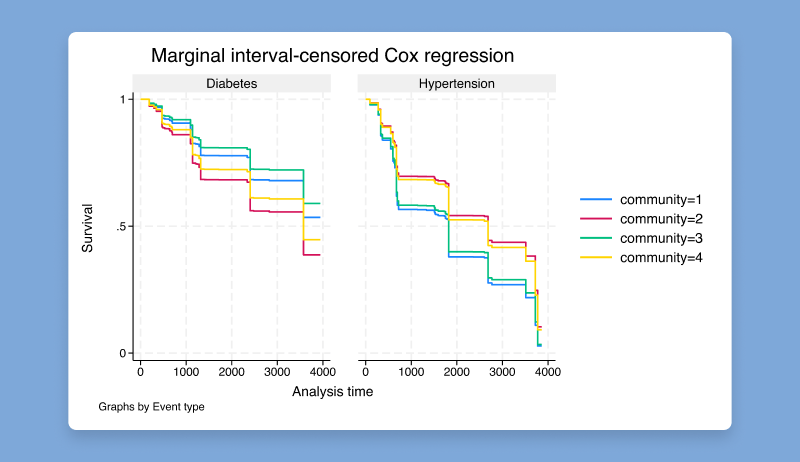
5.1 久期模型
久期模型(duration model)的被解释变量为某事件存续的时间,例如失业持续时间,病人存活的时长等。在原有久期模型的Stata模块基础上(命令均以st开头),针对存在“区间删失”(interval-censored)的多事件数据(multiple-events data),Stata 19提供了估计“边际考克斯比例风险模型”(marginal Cox proportional hazards model)的新命令stmgintcox。
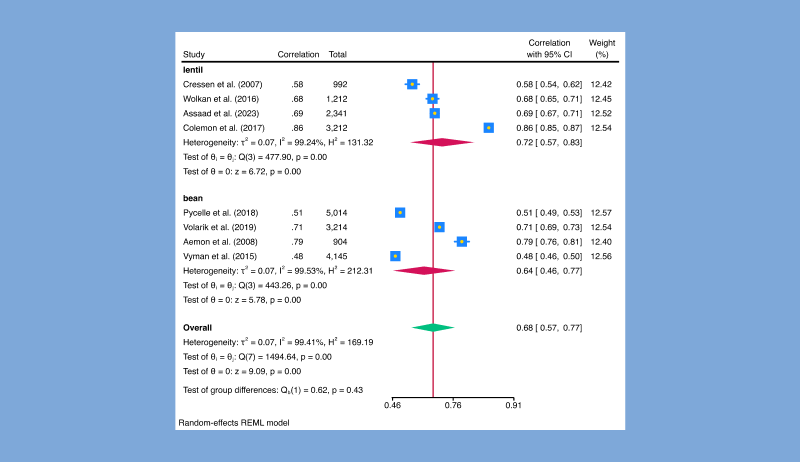
5.2 相关系数的元分析
在文献中,针对同一问题,常常有多项类似的研究,但所得估计结果不尽相同。如何将这些相似研究的结果进行整合,以得到统一的结论,这正是“元分析”(meta-analysis)的目标。在Stata原有的元分析meta命令模块中,Stata 19新增了对于相关系数的元分析功能。相关系数无疑是最重要的描述性统计之一。
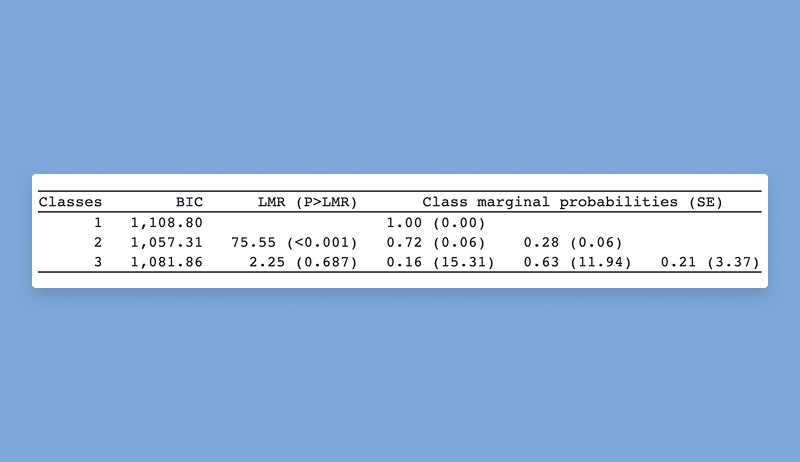
5.3 潜类别模型
“潜类别模型”(latent class model)是一种常见的统计模型,它假设数据来自于若干总体(或类别)的混合,故也称为“有限混合模型”(finite mixture model);例如,三个服从正态分布的总体按照一定比例的混合。如果知道类别的数目,则可使用原有的Stata命令gsem(表示generalized structural equation model)进行估计。
6、Stata基础功能提升
6.1 Do文件编辑器
Stata 19的Do文件编辑器(Do-file Editor)变得更为强大,新增功能包括:
(1)变量名(variable names)、宏(macros)与存储结果(stored results)的自动补全(autocompletion);
(2)方便用户使用的Do文件编辑器模板(Do-file Editor templates);
(3)对当前词(current word)在编辑器中的所有出现之处均提供高亮(highlighting),无论大小写(case-insensitive);并对当前所选内容(current selection)在编辑器中的所有出现之处均提供高亮(highlighting),区分大小写(case sensitive);
(4)括号高亮(bracket hightlighting),即对包含当前光标的括号(the brackets enclosing the current cursor position)提供高亮;
(5)代码折叠功能的提升(code folding enhancement),包括新增的菜单栏目(menu items)“Fold all”(折叠全部可折叠代码), “Unfold all”(展开所有已折叠代码)与“Fold selection”(折叠所选内容)。
6.2 画图
Stata 19的画图功能也变得更为强大,新增功能包括:
(1)通过新增命令twoway heatmap画热图(heat maps),即在变量(x, y)取值的网格上,以小方块的颜色变化来表示对应变量z的取值高低。
(2)通过新增命令twoway rpspikes画“刺形”的点图或范围图(plot points and ranges indicated by spikes),例如展示某统计量及其相应的置信区间。
(3)通过新增命令twoway rpcaps画“带帽刺形”的点图或范围图(plot points and ranges indicated by spikes with caps),例如展示某统计量及其相应的置信区间。
(4)在使用命令graph bar画柱状图/条形图(bar plot)时,可画样本均值及其置信区间,以及在标签与控制条形分组方面的改进(improved labelling, and control of bar groupings)。
(5)在使用命令graph dot画点状图(dot chart)时,可画样本均值及其置信区间,以及在标签与控制点状分组方面的改进(improved labelling, and control of dot groupings)。
(6)在使用命令graph box画箱形图(box plot)时,改进了标签与对箱形分组的控制(improved labelling, and control of box groupings)。
(7)根据变量上色(colors by variable)的选择项colorvar(),可适用于更多的twoway plot命令,包括line, connected, tsline, rconnected及tsrline等。
6.3 制表
Stata 19的制表功能也得以进一步提升,可更方便地创建与定制表格
(1)Stata的制表命令table新增了增加标题的选择项title(),增加脚注的选择项note(),以及将表格导出为指定文件格式(例如Word, LaTex, Excel等)的选择项export()。
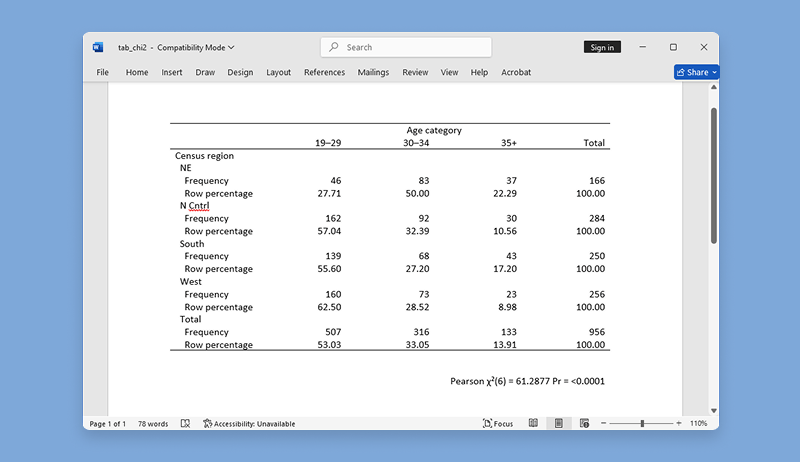
(2)更简便的方差分析表格(easier ANOVA tables)。




评论